« Permettre aux agences de sécurité publique de mieux prévenir la criminalité dans leurs collectivités en générant des prédictions sur les lieux et les moments où de futurs crimes sont les plus susceptibles de se produire », tel est le slogan de PredPol, société éditrice du logiciel de « prédiction policière » (Predicting policing) du même nom. Selon celle-ci, il y aurait eu « 13% de diminution de la criminalité dans un quartier de Los Angeles après 4 mois de mise en service contre une augmentation de 0.4% dans le reste de la ville », le logiciel serait « jusqu’à deux fois plus précis que les analystes spécialisés ». Devant ces prétentions spectaculaires, il est raisonnable d’exiger des preuves spectaculaires. Mais le scepticisme n’est que la première étape du travail critique, investiguer en est la deuxième.
Dans cette perspective et dans le cadre d’un stage de Master 1 en physique à l’Université Joseph-Fourier, j’ai effectué, sous la direction de Guillemette Reviron, un travail de recherche sur ce système. Pour celles et ceux qui souhaiteraient entrer dans les détails de ce travail, les arguments plus techniques sont présentés dans le rapport de stage qui peut être téléchargé ici. Vous pouvez me contacter à cette adresse : benslimane [at] cortecs.org
Le but premier de l’étude était d’évaluer de manière objective les prétentions de Predpol concernant les précisions de l’algorithme. Un tel système pose aussi de nombreux problèmes moraux, éthiques et politiques qui seront développés dans un second temps. Nous allons voir que les résultats de PredPol sont loin d’être exceptionnels et que leur prédiction : « les crimes auront lieu majoritairement dans les zones prédites par notre algorithme complexe » n’est en fait pas plus performante que la prédiction : « les crimes auront lieu majoritairement dans les zones historiquement les plus criminogènes de la ville ».
[toc]
Predpol, la prédiction policière ?
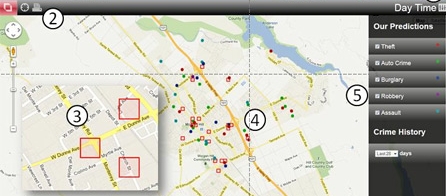
Predpol, par le biais d’une interface cartographique, affiche quotidiennement un ensemble de zones à risque (par exemple : 20 cases de 150m x 150m) pour lesquelles la probabilité qu’un délit se manifeste est importante. Chaque jour, les unités de polices reçoivent la carte avec les prédictions calculées par l’algorithme et sont priées de patrouiller dans ces zones à risque pendant leur temps libre.
Une présentation des résultats fortement biaisée et impactante
Utilisation abusive de graphiques imprécis
Les résultats, tels qu’ils sont présentés par Predpol, impressionnent. En effet, la société proclame sur son site web que son algorithme est deux fois plus précis que les analystes en criminologie. Analysons un instant le graphe (Figure 1) à l’appui des présentations de Predpol.
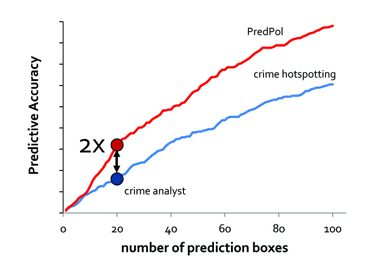
Je n’oserais pas appeler cette figure un graphique étant donné la médiocrité de celui-ci, en effet, le graphique ne respecte en aucune manière les règles de base pour qu’un graphique soit pertinent (voir la section Résultats obtenus pour un exemple de graphique sérieux). Des éléments essentiels devant figurer sur un graphique ne sont pas précisés :
– il n’y a pas de titre
– il n’y a ni échelle, ni origine sur l’axe des ordonnées (axe vertical)
– il n’y a pas de légende : deux courbes (rouge, bleu) pour trois titres (crime analyst, crime hotspotting, Predpol) !
– les marqueurs (cercles bleu et rouge) sont trop larges
Enfin, une telle figure devrait être suivie d’explications basiques sur les résultats :
– on ne sait pas comment est mesurée l’efficacité des prédictions ; les critères de mesure ne sont pas précisés
– les termes « crime analysts » et « crime hotspotting » ne sont pas explicités
Par ailleurs, Predpol déclare que son logiciel est deux fois plus performant que les prévisions des analystes, mais quelques mesures sur le graphe permettent de vérifier que cette valeur est valable dans une unique situation, celle qui correspond à une prédiction pour 20 boîtes ; cette situation est accessoirement celle qui est la plus avantageuse pour Predpol. Entre 1 et 10 boites, en revanche, les deux prévisions se valent. En moyenne, le rapport vaut environ 1,5 lorsque l’on évalue les courbes avec un analyseur graphique (par exemple avec le logiciel libre Engauge-digitizer).
On ne peut donc pas conclure, à la simple lecture de ce graphique, que l’algorithme est deux fois plus précis que les analystes en criminologie sans réaliser une analyse des données plus fine.
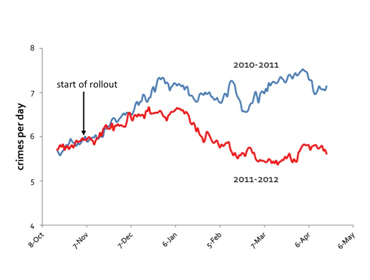
Le deuxième graphique (Figure 2) montrant une diminution de la criminalité est lui aussi trompeur car l’origine de l’axe est absente.
Ces imprécisions ne sont pas anodines : en simplifiant à outrance les données utilisées pour comparer deux pratiques, elles poussent à une analyse « à la hache » d’un phénomène complexe.
Pour une illustration ludique des tours de passe-passe courants que peuvent générer les graphiques, on pourra consulter l’article « Comment tromper avec des graphiques ».
Biais inhérents à la mesure de la criminalité
Les affirmations d’une réduction effective de la criminalité sont à prendre avec précautions, en effet, les chiffres sur la criminalité et la délinquance sont enclins à de nombreux biais, en voici quelques-uns :
-
Délits réels ou constatés : ne sont comptés que les crimes et délits constatés. Un changement dans les procédures d’enregistrement des délits peut facilement augmenter ou diminuer les chiffres de la criminalité sans rendre compte de la réalité. Dans le cas du système Predpol, un système d’enregistrement et de classification des délits est mis en place en même temps que le déploiement du logiciel.
-
Tri sélectif des données :
-
Type de délit : quels délits sont-ils pris en compte lors de l’évaluation ? Si il y a une réduction des vols de voitures mais une augmentation des vols à l’arraché, que faut-il en conclure sur l’efficacité ? Le capitaine de la police d’Alhambra (E-U) semble ne pas voir le problème des vases communicants.1
- Tri géographique et problème des vases communicants : quelle zone est choisie pour évaluer la baisse de la criminalité ? S’il y a une réduction de la criminalité dans les quartiers où Predpol est utilisé, mais une augmentation équivalente dans les quartiers voisins, peut-on en conclure que Predpol est efficace pour réduire la criminalité ? Il s’agirait alors plutôt d’une efficacité à déplacer la criminalité.
-
- L’effet paillasson et prédiction auto-réalisatrice : une définition floue et évasive du terme « délit » permet de valider les prédictions du logiciel selon l’interprétation de l’utilisateur. En effet, Predpol ne précise pas le type de délit prédit, ainsi, un policier orienté par celui-ci pourra interpréter n’importe quelle incivilité comme validant la prédiction. « Quand on cherche, on trouve… »
- L’effet Barnum/Forer ou le problème de l’arbre des possibles : imaginons un policier, en pause, en train de manger un donut gras et collant dans sa voiture, l’ordinateur signale une zone à risque :
- il va sur les lieux, il remet le donut à plus tard :
- il y a un délit qui se produit, le policier valide donc la prédiction du logiciel.
- il n’y a pas de délit, le policier valide aussi la prédiction du logiciel car il a empêché tout incident.
- il ne va pas sur les lieux, il finit son donut :
- Il y a eu un de délit, le policier apprend la nouvelle, il validera la prédiction du logiciel car il aurait dû finir son donut et se déplacer.
- Il n’y a pas eu de délit, le policier finira son énième donut et oubliera l’événement car personne ne lui rappellera qu’il n’y a pas eu de délit.
- il va sur les lieux, il remet le donut à plus tard :
Comme vous pouvez le voir, peut importe la situation, le logiciel semble toujours efficace si les critères d’évaluation ne sont pas plus précis.
- L’effet cigogne : si la mise en place de Predpol est effectuée en même temps qu’une restructuration des services ou un changement dans les procédures de travail, il n’est plus possible de différencier les effets dus au logiciel ou à la restructuration. Le système Predpol est axé sur l’augmentation des patrouilles et il est facilement concevable de penser que la présence d’unité de police fait diminuer la criminalité. Dans ce cas, il faut pouvoir différentier l’effet propre de Predpol à l’effet contextuel.
Pour un travail pratique sur le sujet, voir l’article « Sciences politiques & Statistiques – TP Analyse de chiffres sur la délinquance ».
Une forte médiatisation
Souvent décrit par les journalistes comme la concrétisation du film Minority Report (2002) de Steven Spielberg, Predpol a été l’objet d’une promotion très importante. De nombreux médias ont évoqué le sujet, une simple recherche sur un moteur de recherche d’actualité permet d’en recenser des centaines, y compris dans les médias des plus grands groupes de presse. Le « Time Magazine » désigna Predpol comme l’une des « 50 inventions de l’année 2011 » 2 . Concernant le développement commercial, le système est mis en place dans plus d’une vingtaine de villes aux États-Unis et une au Royaume-Uni. Plusieurs articles de recherche ont été subventionnés par des fonds publics nationaux étasuniens provenant par exemple du département de recherche de la défense (Army Research Office, fond 58344-MA) ainsi que de l’organisme public de financement de la recherche équivalent du CNRS, la National Science Foundation, avec un financement d’un montant de 1 008 105 $ pour des recherches collectives (Fond DMS-0968309 : Mathématiques sur la criminalité urbaine à grande échelle). La problématique du financement public de la recherche au profit d’agents privés est rarement débattue, mais la question est cruciale tant nos sociétés technologiques fonctionnent grâce à ces modèles de connivence.
Pour approfondir la question, voir l’article Main basse sur la science publique : le «coût de génie» de l’édition scientifique privée.
Méthodes
La première partie de l’étude a porté sur la recherche d’informations que nous avons recoupées afin d’établir un profil complet du système développé par Predpol Inc.
Nous avons contacté la société Predpol Inc localisée à Santa Cruz (Californie, États-Unis) ainsi que la police du comté du Kent située au Royaume-Uni et utilisant Predpol depuis le mois de décembre 2012. Les démarches envers elles n’ont donné aucune suite exploitable.
L’ensemble des informations recueillies provient d’articles de recherche, de sites internet (société Predpol Inc, services de police), de présentations du produit, de conférences en ligne, de bases de données publiques ainsi que de rapports confidentiels anonymisés et déclassifiés.
Pseudo-études et pseudo-expérimentations
L’étude la plus citée par les médias est une étude réalisée pendant six mois dans la division de Foothill à Los Angeles (Californie, États-Unis) en 2011. Pour autant, aucun article scientifique n’est paru à son sujet et les résultats promus par la société Predpol Inc et par les unités de Police sont trop peu développés, ils se sont avérés inexploitables. Par ailleurs, la gestion des données criminelles est effectuée par une société privée au niveau de la police de Los Angeles, « THE OMEGA GROUP ». Cette société rend accessible au public les données géo-référencées des délits par l’interface CrimeMapping.com™ mais les données sont restreintes aux délits récents (moins de six mois). Sans réponse de Prepol, sans publication, il n’a donc pas été possible d’étudier de manière sérieuse l’expérimentation.
La seule étude exploitable est l’étude théorique rétrospective effectuée avec des données de Chicago en 2014. Deux raisons nous ont amenés à nous concentrer sur le cas de Chicago. D’une part, les données sont publiques et libres d’accès3. La base de données contient un peu plus de 5 500 000 délits répertoriés de 2001 jusqu’à aujourd’hui avec pour champs : le type de délit, la description, les coordonnées GPS, l’heure, la date, etc. D’autre part, les seules études sujettes à une analyse approfondie ont été celles concernant la ville de Chicago avec un bref rapport (Predpol Inc, 2013)4 et une publication (Mohler, 2014)5 parue dans l’International Journal of Forecasting de Juillet-Septembre 2014. Cette dernière publication d’une revue scientifique à comité de lecture est la continuité du premier rapport mais développe une analyse beaucoup plus complète.
Interface cartographique
Un long travail a été de développer une interface web permettant d’afficher, tel Predpol, l’ensemble des délits présents dans une base de données sur une carte type OpenStreetMap. J’ai aussi pu reproduire le quadrillage réalisé par Predpol en me basant sur une capture d’écran. J’ai donc pu vérifier que les algorithmes développés fonctionnaient correctement en visualisant leurs effets sur la carte géographique.
Pour avoir un aperçu et tester l’application développée, c’est par ici : (disponible bientôt)
Simulations et analyses effectuées
Le but de l’étude fut donc de comparer les résultats obtenus par Predpol en terme d’efficacité de prédiction avec des méthodes d’analyse basique pour pouvoir évaluer l’efficacité propre de Predpol.
Base de données et conditions d’expérimentation.
J’ai téléchargé la même base de données qui est décrite dans les articles (Predpol Inc, 2013 et Mohler, 2014). Celle-ci concerne uniquement les homicides et délits avec armes à feu entre 2007 et 2012. J’ai utilisé les mêmes critères de sélection que Predpol et j’ai obtenu une base de plus de 78 000 données concernant les homicides, agressions sexuelles, voies de fait, coups et blessures, vols et ports d’armes illégaux.
Développement d’algorithmes concurrents
Voici comment nous avons procédé pour évaluer l’efficacité de nos prédictions : chaque jour nous avons généré une carte selon les différents algorithmes ainsi qu’un certain nombre de zones sélectionnées comme prédiction d’un ou plusieurs délits pour la journée. À la fin de celle-ci, il était compté le nombre de délits commis dans les zones précédemment choisies par rapport au nombre de délits commis dans toute la carte.
Exemple :
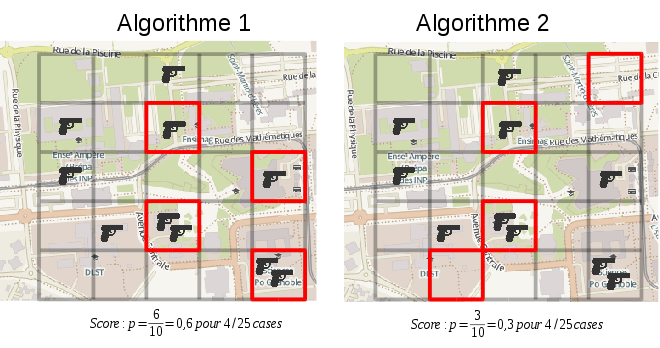
Notion de points chauds
Une carte des points chauds est une carte représentant le taux de criminalité d’une zone géographique. On la représente habituellement comme une carte des températures avec une couleur bleue pour les zones avec peu de criminalité jusqu’au rouge pour les zones criminogènes. Le code couleur peut être défini par le nombre de délits enregistrés dans l’année.
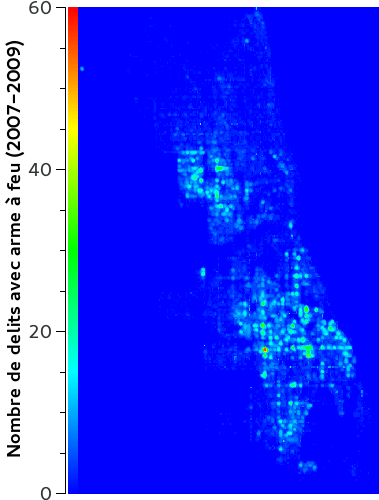
Algorithmes mis en compétition avec Predpol
J’ai développé trois algorithmes et les ai comparés à Predpol.
- Prédiction aléatoire : il est important de comparer la prédiction de Predpol au modèle le plus naïf. Cet algorithme fait des prédictions sans tenir compte du contexte (criminalité passée, densité de population…). Toutes les zones ont la même probabilité d’être désignées comme zone de prédiction (s’il y a 253 zones, chaque zone a 1 chance sur 253 d’être tirée au sort).
- Prédiction aléatoire avec points chauds : cette technique est une amélioration de la précédente. Cette fois-ci, on prend en compte les spécificités du terrain. On effectue un tirage aléatoire pondéré par le taux de criminalité. Il y aura donc plus de chance qu’une zone à forte activité criminelle soit sélectionnée par l’algorithme.
- Prédiction par meilleur rang avec points chauds : la prédiction par meilleur rang utilise les mêmes principes que les algorithmes avec points chauds pour la pondération. Cependant, c’est au niveau de la sélection que cela diffère : au lieu d’effectuer une sélection aléatoire, les zones à plus haut risque sont toujours choisies prioritairement, chaque division de la carte est triée par taux de criminalité, et les n-ièmes premières divisions sont choisies comme étant nos prédictions. En résumé, on envoie toujours les unités de police dans les quartiers chauds et dans les quartiers les plus chauds prioritairement.
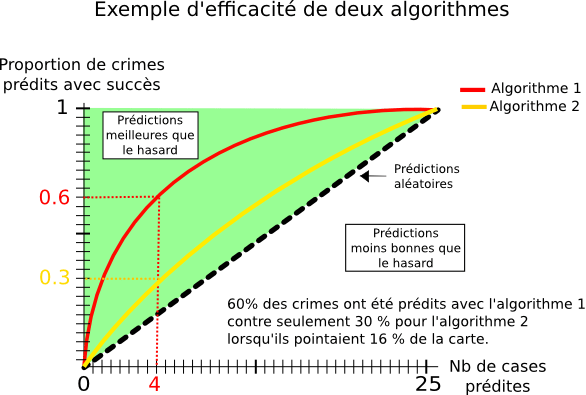
Résultats et discussion
Rappelons-nous que l’on compare nos résultats à ceux de l’étude (Mohler, 2014). Le résultat principal de cette étude est l’obtention d’une courbe donnant la proportion p de crimes correctement prédits en fonction du nombre de cases prédites chaque jour. Le score p est mesuré comme étant le nombre de délits figurants à l’intérieur de toutes les cases générées par rapport au nombre total de délits constatés (Figure 3). Si l’on prend l’exemple de la figure 3, le score de l’algorithme 1 sera représenté par la coordonnée (4;0,6), le score de l’algorithme 2 sera représenté par la coordonnée (4;0,3).
Voici un exemple de graphique comparant les deux précédents algorithmes fictifs :
Résultats obtenus
Le résultat principal de l’étude (Mohler, 2014) est l’obtention de la courbe que j’ai appelée « Predpol (Mohler, 2014) ». L’échelle choisie dans la publication (Mohler, 2014) diffère du précédent graphique (figure 4), ainsi, le graphique n’est pas complet, c’est-à-dire qu’un zoom autour de l’origine a été effectué. Pour avoir un moyen de comparaison avec la figure 4, on peut se servir des droites « Aléatoire » qui devraient se superposer si les graphiques avaient effectivement les mêmes échelles.
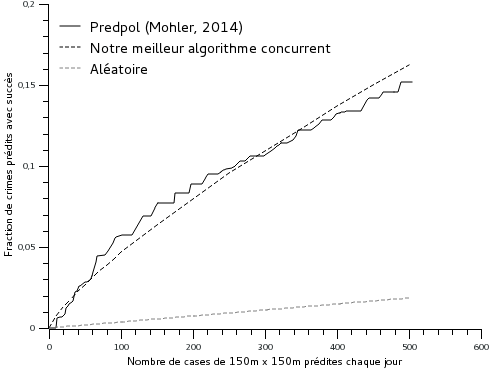
versus nombre de cases prédites chaque jour. — Comparaison avec la publication (Mohler, 2014, Fig. 1.)
Le principal résultat que l’on obtient est que l’algorithme le plus performant (meilleur rang) obtient des scores de prédiction très proches de la courbe (Mohler, 2014, Fig.1. « marked point process »). Sur l’intervalle [250,500] préconisé pour un déploiement à Chicago (Mohler, 2014), notre algorithme est légèrement plus performant. Pour une caractérisation plus précise, se référer à l’article joint.
Pourquoi obtient-on de tels résultats ?
La répartition spatiale des délits permet d’expliquer en partie l’efficacité d’un algorithme de meilleur rang comparé à des techniques plus fines utilisées par Predpol. La courbe (Figure 6) représentant la fraction de délits située dans une fraction d’espace donnée nous indique le fait que la répartition est très inégale. Lorsque l’on quadrille la ville, la plupart des délits on toujours lieu dans les mêmes secteurs, ainsi 80 % des délits à arme à feu ont eu lieu dans 20 % du quadrillage. Cette découverte relativise grandement l’autosatisfaction de Predpol qui se félicite de prédire 50% des délits en pointant 10.3% de la surface de la ville (Predpol Inc, 2013). Le graphique nous montre que 50 % des délits ont lieu dans 7,5 % de la ville. Étant donné que la criminalité évolue peu, il suffit de prédire toujours les mêmes lieux « à risque » pour être aussi performant que Predpol : c’est ce que démontre notre algorithme concurrent.
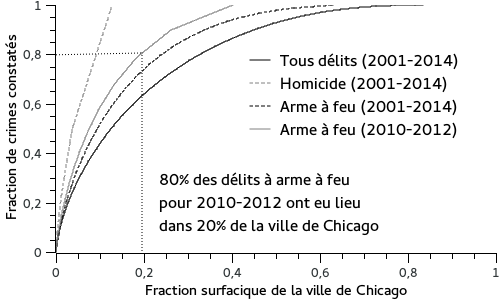
surfacique de la ville de Chicago
Conclusion
Les résultats obtenus avec l’analyse rétrospective, nous permettent d’avoir de sérieux doutes sur l’efficacité propre de Predpol en condition réelle. Ceci amène à continuer l’investigation en recontactant les auteurs des études (Predpol Inc, 2013 et Mohler, 2014) afin de les confronter à nos résultats. D’autres suites seront envisageables selon leur réponse.
Au-delà des aspects les plus techniques, on peut se demander, si la démarche de Predpol ne désyncrétise pas la question de la criminalité en laissant penser qu’il suffit de prédire les délits pour en diminuer le nombre. Predpol et sa médiatisation véhiculent ainsi une idée répandue, « simple » et séduisante oubliant de facto les facteurs sociologiques amenant aux comportements délictueux. La question fondamentale des inégalités de répartition des richesses est, par exemple, rarement débattue. En effet, cette réflexion est beaucoup plus impliquante à long terme qu’un logiciel spectaculaire.
Annexe
Article
L’étude (4 pages) peut être téléchargée ici :
Ismaël Benslimane, Étude critique d’un système d’analyse prédictive appliqué à la criminalité : Predpol®. CorteX Journal, 2014.
Interface cartographique
Pour avoir un aperçu et tester l’application développée, c’est par ici : (disponible bientôt).
Outils utilisés*
Pour traiter les données, nous avons utilisé un système de base de données MySql, l’interface cartographique a été développée en langage web (Html, PhP, Javasript), et l’algorithme de sélection en btree a été programmé en Python. Pour l’analyse des graphiques imprimés, nous avons utilisé Engauge-digitiser. Le traitement des données a été effectué avec Scidavis. Le traitement statistique fut réalisé avec le logiciel R.
*Tous ces logiciels ou technologie sont libres.
Bibliographie
Références
- George O Mohler, Martin B Short, P Jeffrey Brantingham, Frederic Paik Schoenberg, and George E Tita. Self-exciting point process modeling of crime. Journal of the American Statistical Association, 106(493), 2011.
-
George O Mohler. Marked point process hotspot maps for homicide and gun crime prediction in chicago. International Journal of Forecasting, 30(3) :491–497, 2014.
Sites web
- Predpol : www.predpol.com
- Los Angeles Police Departement : www.lapdonline.org
- Kent Police : www.kent.police.uk
Bases de données
- The Omega Group (États-Unis) : www.crimemapping.com
- Police britannique : data.police.uk
- Ville de Chicago (États-Unis) data.cityofchicago.org
Rapports
- Rapport déclassifié concernant l’expérimentation effectuée par la Police du Kent (RU) : Predpol operational review – initial findings, Kent Police, 2012.
- Rapport concernant l’expérience avec les données de Chicago (EU). PredPol Predicts Gun Violence, Predpol Inc, 2013.
- Présentation concernant l’expérience de Los Angeles, Foothill (EU) :The Los Angeles Predictive Policing Experiment, Charlie Beck, Chief of Police
Los Angeles Police Department, 2012.

 Il semblerait que Perceval et Karadoc, le duo culte de la série Kaamelott, n’aient pas suivi de cours d’autodéfense intellectuelle, pour preuve : un des plus hilarants exemples de
Il semblerait que Perceval et Karadoc, le duo culte de la série Kaamelott, n’aient pas suivi de cours d’autodéfense intellectuelle, pour preuve : un des plus hilarants exemples de 
 « There Is No Alternative » (TINA, en français « Il n’y a pas d’autre choix »), tel est le morose slogan repris par Margaret Thatcher
« There Is No Alternative » (TINA, en français « Il n’y a pas d’autre choix »), tel est le morose slogan repris par Margaret Thatcher