
A l’occasion d’une conférence donnée à Marseille, Nicolas Gauvrit, Maître de Conférences à l’Université d’Artois et chercheur au laboratoire de didactique de l’Université Paris VII, a accepté de répondre à quelques-unes de nos questions. Nous partageons ici ses réflexions sur le thème de la psychanalyse notamment mais également sur des sujets plus généraux comme le rationalisme, la prise en charge de l’autisme, etc. (La prise de son annexe n’a pas fonctionné, désolé).
Denis Caroti
-
Zététicien, rationaliste, sceptique ? Comment Nicolas se définit-il ? - Agir de façon rationnelle ? Peut-on croire de façon rationnelle ?
- L’inconscient comme fondement des psychanalyses
- Les psychanalyses sont-elles « scientifiques » ?
- Quels sont les critères pour dire qu’une pratique est « scientifique » ?
- Peut-on tester certaines hypothèses psychanalytiques ?
- Des hypothèses psychanalytiques ont-elles été validées ?
- Psychanalyse et idées reçues
- Le refoulement : une idée reçue ?
- Le lapsus : idée reçue ?
- Lacan et les mathématiques : imposture intellectuelle ?
- Psychanalyse et autisme : sophisme « du juste milieu »
- Psychanalyse : traiter les causes de l’autisme ?
- Les livres qui ont compté
- Développer science et esprit critique : un outil de transformation sociale ?
- Bibliographie
| [dailymotion id=xr55xb] | Zététicien, rationaliste, sceptique ? Comment Nicolas se définit-il ?Pourquoi ? Quel est le terme qui convient le mieux pour parler de ses travaux ? |
| [dailymotion id=xr56j2] | Agir de façon rationnelle ? Peut-on croire de façon rationnelle ? |
| [dailymotion id=xr5dz0] | L’inconscient comme fondement des psychanalyses |
| [dailymotion id=xr56jo] | Les psychanalyses sont-elles « scientifiques » ? |
| [dailymotion id=xr56jv] | Quels sont les critères pour dire qu’une pratique est « scientifique » ? |
| [dailymotion id=xr56k4] | Peut-on tester certaines hypothèses psychanalytiques ? |
| [dailymotion id=xr5f6o] | Des hypothèses psychanalytiques ont-elles été validées ? |
| [dailymotion id=xr5fei] | Psychanalyse et idées reçues |
| [dailymotion id=xr5fv9] | Le refoulement : une idée reçue ? |
| [dailymotion id=xr5g75] | Le lapsus : idée reçue ? |
| [dailymotion id=xr5gfc] | Lacan et les mathématiques : imposture intellectuelle ? |
| [dailymotion id=xr5hcm] | Psychanalyse et autisme : sophisme « du juste milieu » |
| [dailymotion id=xr5i2g] | Psychanalyse : traiter les causes de l’autisme ? |
| [dailymotion id=xr5isp] | Les livres qui ont compté |
| [dailymotion id=xr5iut] | Développer science et esprit critique : un outil de transformation sociale ? |
 |
 |
 |
|
Bibliographie :
– Le singe en nous, Frans de Waal, Fayard (2006).
– Mensonges freudiens, Jacques Bénesteau, Pierre Mardaga éditeur (2002).
– Impostures intellectuelles, A.Sokal & J.Bricmont, Odile Jacob (1997).


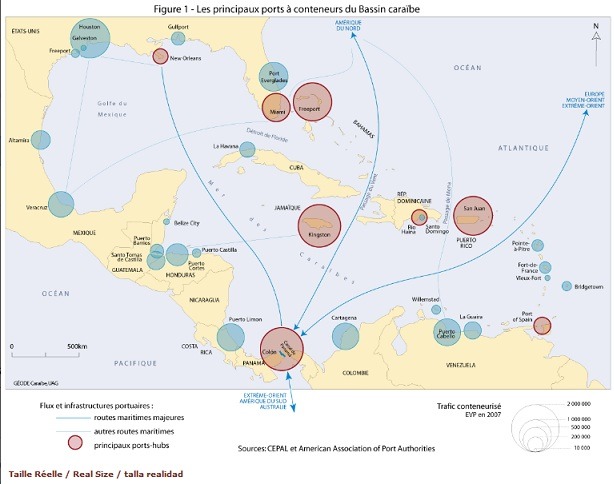







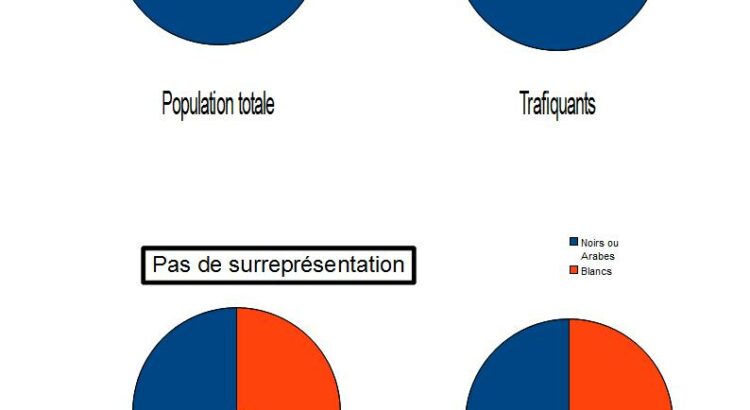
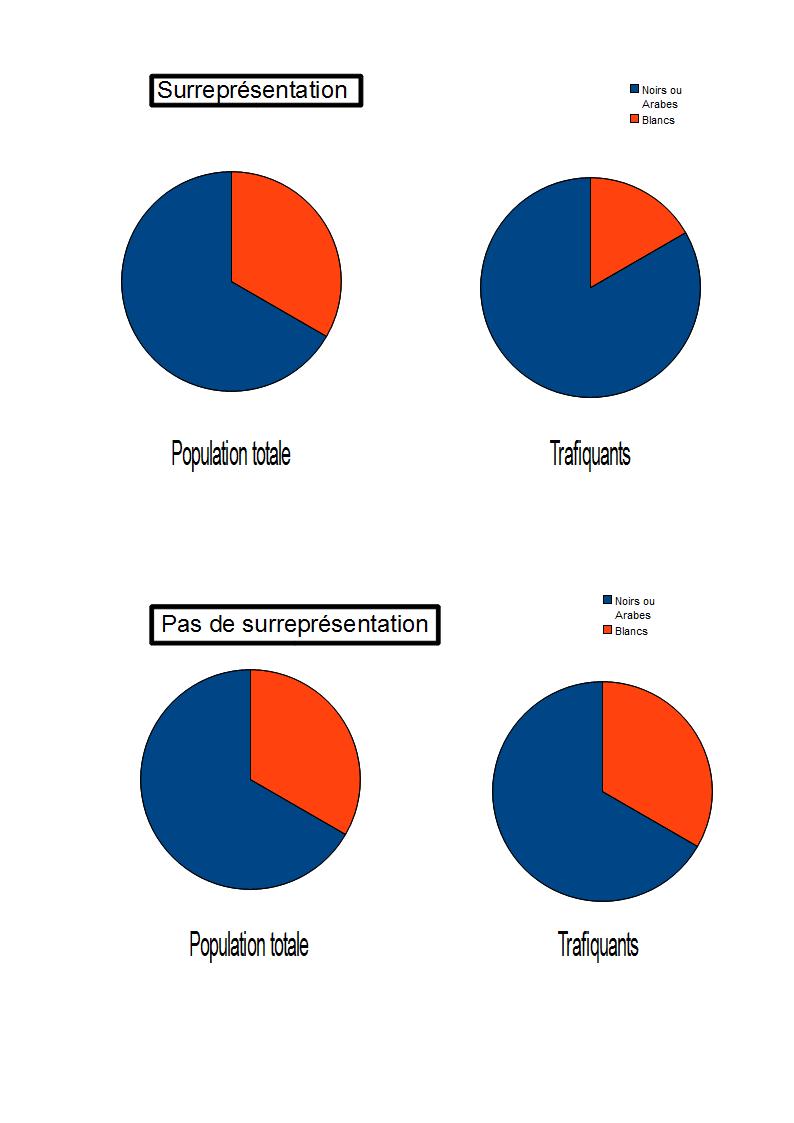

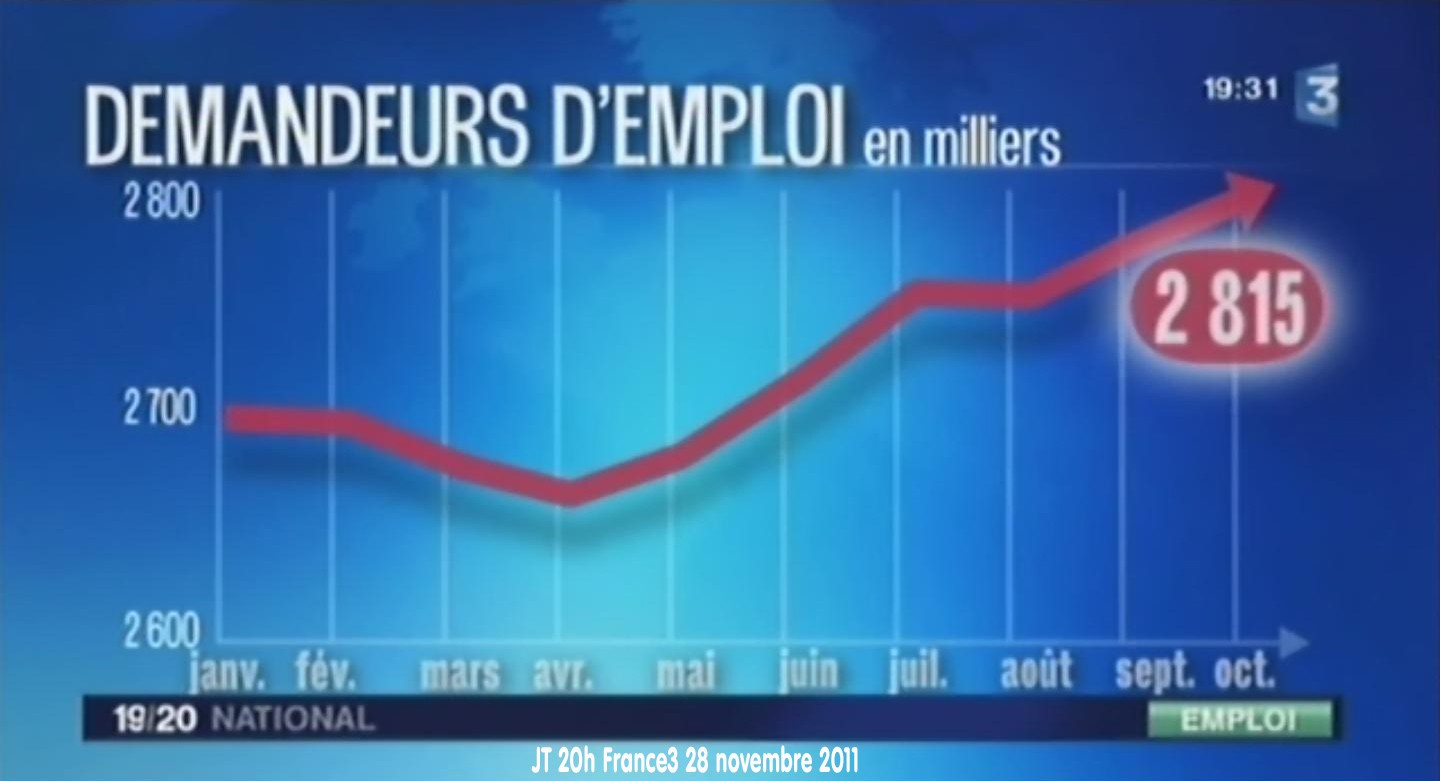




 scolaires inférieurs à la moyenne. Il se peut que fumer soit la cause de moins bons résultats. Mais il se peut aussi qu’avoir de moins bons résultats conduise à fumer. Ou encore que les gens plus sociables tendent à la fois à fumer du cannabis et à prendre leurs résultats moins au sérieux.
scolaires inférieurs à la moyenne. Il se peut que fumer soit la cause de moins bons résultats. Mais il se peut aussi qu’avoir de moins bons résultats conduise à fumer. Ou encore que les gens plus sociables tendent à la fois à fumer du cannabis et à prendre leurs résultats moins au sérieux. « Avant, le Père Noël était vert, Coca-Cola a fait une pub avec un Père Noël rouge, donc Coca-Cola a changé la couleur du Père-Noël ! » (merci à Nico, Hoaxbuster Team).
« Avant, le Père Noël était vert, Coca-Cola a fait une pub avec un Père Noël rouge, donc Coca-Cola a changé la couleur du Père-Noël ! » (merci à Nico, Hoaxbuster Team).
