Quel sera le record du 100m en 2100 ? C’est une question que se sont posée des chercheurs anglais dans un article de 2004 et qui, pour y répondre, ont déployé leurs outils statistiques de manière assez maladroite. Une erreur qui n’est qu’une perche tendue pour faire une lecture critique d’un article scientifique et montrer comment on peut prédire n’importe quoi en ayant l’air scientifique.
Et quand on dit “statistiques”, on entend déjà un chuchotement dans l’oreille qui nous rappelle à la prudence avec ces mots popularisés1 par Mark Twain : “Il y a trois sortes de mensonges : les mensonges, les sacrés mensonges et les statistiques” 2
Mensonge ou erreur, peu importe, toujours est-il qu’il est facile de (se) tromper avec des chiffres. Et une de ces erreurs potentielles concerne les prédictions que l’on peut faire à partir des données passées. Pour faire de telles prédictions, bien souvent la méthode est la suivante : on observe les données passées puis on prolonge la tendance observée dans le futur.
Il est donc nécessaire de décider comment prolonger ces données : c’est ce que l’on appelle le modèle de régression. Et ce choix peut-être assez fallacieux. Pour illustrer ceci, reprenons l’exemple des performances athlétiques sur 100m.
Les Jeux-Olympiques de 2156 seront historiques !
Pour prédire l’avenir des perfomances athlétiques, une manière de faire consiste à analyser l’évolution des performances passés pour en déduire l’évolution future. On trace sur un graphique les données passées, on trace une courbe qui a l’air de coller aux données et on peut prédire le futur ! Facile !
C’est ce qui a, donc, été fait dans un article publié en 2004 dans la revue Nature et dont le titre peut se traduire par “Un sprint historique aux Jeux Olympiques de 2156 ?”3.
Les auteurs de l’étude ont collecté tous les temps des champions olympiques, masculins et féminins, du 100m (depuis 1900 pour les hommes et -seulement- depuis 1928 pour les femmes, et jusqu’en 2004 date de publication de l’article). Ces données ont ensuite été tracées sur un graphique et approchées par une courbe supposée représenter la tendance (voir ci dessous).
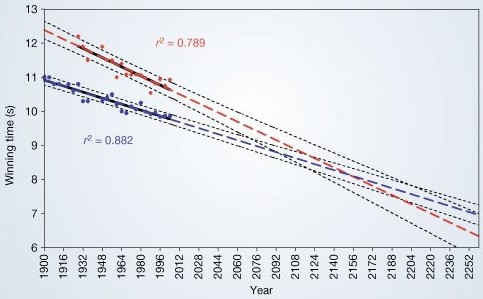
Les points bleus et rouge correspondent aux données passées : temps du vainqueur (respectivement masculin et féminin) du 100m aux JO par année.
Les pointillés épais représentent la prédiction future et les pointillés fins représentent les intervalles de confiances.
Ainsi l’étude prédit qu’en 2100 le temps féminin du 100m olympique sera d’environ 8.9sec et le record masculin sera d’environ 8.5sec. Il prédit également qu’aux Jeux Olympiques de 2156, le temps de la course féminine pourrait, pour la première fois, passer en dessous de celui de la course masculine. En prenant en compte une marge d’erreur, ils prédisent plus exactement que ce dépassement devrait avoir lieu entre 2064 et 2788 (!)
Cette information a été reprise dans différents médias, par exemple dans Les Echos, sur RDS média sportif canadien, ou en anglais dans The Telegraph ou dans Manchester Eveningnews.

Quelques critiques générales peuvent être émises sur ce résultat, notamment sur la qualité des données qui sont assez peu nombreuses (elle ne comprend qu’une information tous les 4 ans; d’autres articles sur le sujet, considèrent les meilleures performances annuelles) et pas très consistantes (le chronométrage et le règlement ont évolué pendant cette période).
Mais la critique principale concerne le modèle de régression utilisé, autrement dit le choix des tracés bleu et rouge supposés approximer les données.
Préparez le chronométrage négatif
Les auteurs de l’étude proposent d’utiliser une régression linéaire, c’est-à-dire une ligne droite qui passe au plus près des données. Ce choix peut être tout à fait opportun si le phénomène étudié correspond effectivement à une évolution linéaire, au moins localement. Mais est-ce le cas ici ?
Avec le jeu de données qui est proposé, on s’aperçoit qu’une approximation avec une droite semble, en effet, assez bien coller aux données et c’est ce que remarquent les auteurs : “Une gamme de modèles a été testée, […]. Les modèles linéaires (proposés ici) ont donc été adoptés car ils représentaient l’option la plus simple.”4.
Il semble donc que localement, à l’échelle de quelques décennies l’utilisation d’un modèle linéaire pourrait être pertinent.
Mais vous avez certainement remarqué le piège ici : en suivant les prédictions de ce modèle, dans un futur lointain, on finit par tomber sur des résultats absurdes : les temps finiront par arriver à 0s (aux alentours de 2615 pour les femmes et de 2876 pour les hommes) puis négatif (les Jeux Olympiques de l’an 3000 devraient se gagner en -6,67sec pour les femmes et en -1,39sec pour les hommes !). Cette absurdité a d’ailleurs été pointée du doigt dans le numéro suivant de Nature par la chercheuse en biostatistiques Kenneth Rice 5Si l’on prolonge dans le passé, on remarque aussi que les premiers athlètes olympiques (vers -800) auraient couru le 100m en environ 41 secondes pour les hommes et 59 secondes pour les femme (s’il y en avait eu).
Pour comparaison, le record actuel du 100m des plus de 105 ans est de 34”50).
Dans ce cas, l’utilisation d’une régression linéaire pour modéliser l’évolution des performances en sprint sur le long terme n’est pas du tout adaptée et ne nous dit en réalité rien de très intéressant sur les Jeux Olympiques de 2156.
Une critique de l’utilisation d’un modèle linéaire dans cette situation a également été publiée dans le numéro suivant de Nature par Weia Reinboud 6 (qui n’est pas une scientifique mais une athlète).
Affutez son regard critique sur les modèles de régression
Un exercice intéressant consisterait à réfléchir, en premier lieu, aux propriétés que doit avoir un bon modèle de régression, autrement dit quelle forme devrait avoir la courbe pour approximer les données de manière cohérente.
Dans le cas de la prédiction des performances athlétiques futures, en voici trois :
- Comme on l’a vu, le modèle ne devrait pas décroitre indéfiniment. La courbe d’approximation doit atteindre un minimum, on dit qu’elle doit avoir une borne inférieure.
- Cette borne inférieure doit être strictement positive (évidemment, le temps de course ne peut être ni négatif, ni nul).7.
- Si l’on souhaite étendre l’extrapolation dans le passé pour estimer le meilleur coureur à chaque époque, il faut également que le modèle aie une borne supérieure.
Ces contraintes théoriques étant établies (et possiblement d’autres), il est alors possible de choisir un modèle de régression qui les respecte. C’est ce qui est fait par exemple dans l’image ci-dessous extrait d’un autre article8 sur cette même problématique.
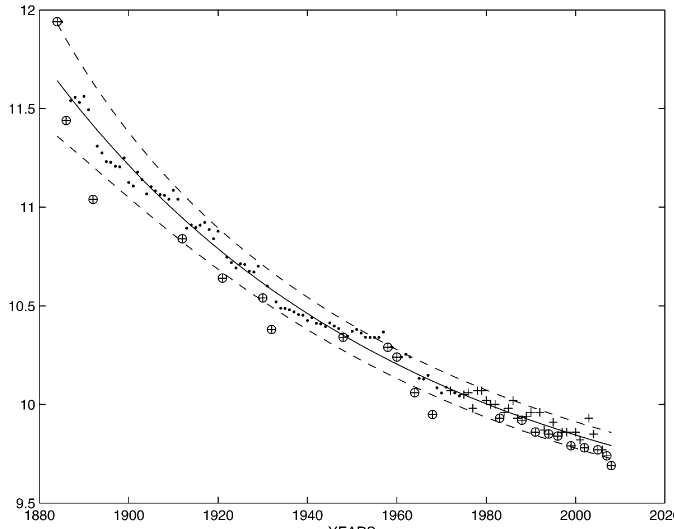
Le modèle de régression utilisé ici (en trait plein) a une pente qui diminue dans le temps ce qui correspond bien à un phénomène qui a une borne inférieure.
Une fois le modèle choisi, les paramètres doivent être ajustés pour coller au plus près aux données existantes et pouvoir ainsi prédire la tendance future.
Cette recherche d’un modèle de régression adéquat qui est ensuite ajusté aux données illustre le fait que souvent, un résultat scientifique robuste se nourrit d’une part d’une cohérence théorique et d’autre part d’une conformité aux données factuelles.
Alors évidemment ici l’enjeu est minimal et si ces chercheurs anglais et leurs prédictions pour 2156 ont fait cette erreur, par maladresse ou pour le buzz, les conséquences sont négligeables.
Il peut, cependant, être utile de garder à l’esprit que faire des prédictions futures à partir de données passées est assez périlleux et peut amener à des conclusions hasardeuses. Si l’on se soustrait à une rigueur scientifique, aux méthodes mathématiques qui encadrent ce type d’estimation et que l’on confie au cerveau humain le soin de tracer les lignes qui prolongent des tendances, il y a fort à parier que l’on retrouvera les biais que l’on connait déjà par ailleurs.
Bonus
Et en bonus quelques planches supplémentaires de xkcd qui n’en finit pas d’extrapoler des données au delà du raisonnable.
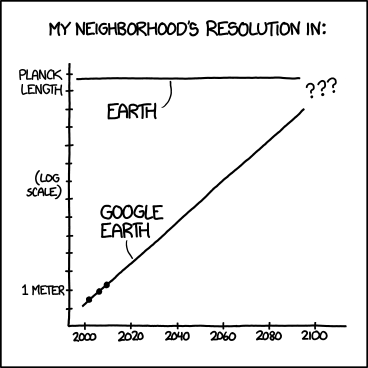
Il prédit qu’en 2036, le mot durable apparaitra en moyenne une fois par page; qu’en 2061 ce sera en moyenne une fois par phrase puis qu’en 2109, les phrases ne seront composées que du mot durable répété inlassablement. Au-delà de cette date, c’est « terra incognita ».






 est ce que l’on cherche à évaluer: la vraisemblance d’une affirmation à partir de preuves. Plus précisément, on cherche à calculer l’évolution de la confiance à accorder en une affirmation lorsque une nouvelle preuve est disponible. Cette quantité est aussi appelée probabilité a posteriori puisqu’elle correspond à la vraisemblance de l’affirmation après avoir pris en compte la preuve.
est ce que l’on cherche à évaluer: la vraisemblance d’une affirmation à partir de preuves. Plus précisément, on cherche à calculer l’évolution de la confiance à accorder en une affirmation lorsque une nouvelle preuve est disponible. Cette quantité est aussi appelée probabilité a posteriori puisqu’elle correspond à la vraisemblance de l’affirmation après avoir pris en compte la preuve. représente la probabilité a priori. C’est à dire la vraisemblance de l’affirmation avant de prendre en compte la preuve. C’est un des principes fondamentaux du bayésianisme : notre croyance en une affirmation évolue sans cesse en fonction des nouvelles preuves qui nous parviennent.
représente la probabilité a priori. C’est à dire la vraisemblance de l’affirmation avant de prendre en compte la preuve. C’est un des principes fondamentaux du bayésianisme : notre croyance en une affirmation évolue sans cesse en fonction des nouvelles preuves qui nous parviennent. est la probabilité a priori d’observer la preuve. Insistons: ces deux dernières probabilités (
est la probabilité a priori d’observer la preuve. Insistons: ces deux dernières probabilités ( , et est également appelée « fonction de vraisemblance », ou simplement « vraisemblance ».
, et est également appelée « fonction de vraisemblance », ou simplement « vraisemblance ». : « Il y a des oiseaux dans les combles à l’origine des phénomènes ». J’y attribue une probabilité de
: « Il y a des oiseaux dans les combles à l’origine des phénomènes ». J’y attribue une probabilité de  .
. : « Il n’y a pas d’oiseau dans les combles et la maison est vraiment hantée ». J’y attribue une probabilité
: « Il n’y a pas d’oiseau dans les combles et la maison est vraiment hantée ». J’y attribue une probabilité  ça paraît fou mais la croyance est tenace dans la famille et dans le village.
ça paraît fou mais la croyance est tenace dans la famille et dans le village. qui va me permettre de mettre à jour mes croyances. On peut estimer la probabilité de trouver une plume là sachant qu’il y a des oiseaux dans les combles
qui va me permettre de mettre à jour mes croyances. On peut estimer la probabilité de trouver une plume là sachant qu’il y a des oiseaux dans les combles  : c’est commun de trouver des plumes mais encore fallait il qu’elle passe par cette petite ouverture. De même on estime la probabilité de trouver une plume sachant qu’il n’y a pas d’oiseau
: c’est commun de trouver des plumes mais encore fallait il qu’elle passe par cette petite ouverture. De même on estime la probabilité de trouver une plume sachant qu’il n’y a pas d’oiseau  : c’est très peu probable, il aurait fallu que quelqu’un l’amène ici. On peut enfin calculer la probabilité de trouver une plume
: c’est très peu probable, il aurait fallu que quelqu’un l’amène ici. On peut enfin calculer la probabilité de trouver une plume  grâce à la formule suivante
grâce à la formule suivante .
.

 pour l’affirmation
pour l’affirmation  pour l’affirmation
pour l’affirmation  pour expliquer la même preuve P. les formules de Bayes s’écrivent alors :
pour expliquer la même preuve P. les formules de Bayes s’écrivent alors :
 .
. multipliée par la probabilité d’observer la preuve
multipliée par la probabilité d’observer la preuve  , mais bien le produit de cette probabilité avec la probabilité d’observer
, mais bien le produit de cette probabilité avec la probabilité d’observer  : Les chats aiment manger des souris;
: Les chats aiment manger des souris; : Je n’ai pas connaissance de souris ayant une telle capacité;
: Je n’ai pas connaissance de souris ayant une telle capacité; : Je ne connais pas bien cette personne, mais il n’est pas impossible que ce soit un tour de magie.
: Je ne connais pas bien cette personne, mais il n’est pas impossible que ce soit un tour de magie. : Seulement 10 secondes pour manger une souris et ne laisser aucune trace… ça me parait suspect;
: Seulement 10 secondes pour manger une souris et ne laisser aucune trace… ça me parait suspect;  : Si la souris avait un tel pouvoir elle aurait en effet sûrement disparu;
: Si la souris avait un tel pouvoir elle aurait en effet sûrement disparu;  : Si Monsieur M. est magicien alors il est très probable que la disparition de la souris soit son tour de magie. En ne regardant que cette « vraisemblance », c’est alors le voyage inter-dimensionnel qui est à privilégier.
: Si Monsieur M. est magicien alors il est très probable que la disparition de la souris soit son tour de magie. En ne regardant que cette « vraisemblance », c’est alors le voyage inter-dimensionnel qui est à privilégier.


 , où
, où  est une quantité très petite. Pour que cette affirmation, une fois pris en compte le nouvel élément de preuve, soit vraisemblable, il faut donc une preuve qui mène à
est une quantité très petite. Pour que cette affirmation, une fois pris en compte le nouvel élément de preuve, soit vraisemblable, il faut donc une preuve qui mène à  . On peut montrer que cette condition
. On peut montrer que cette condition
 on a
on a  et donc
et donc
 n’est pas suffisante ! Il faut également que
n’est pas suffisante ! Il faut également que  et donc que la probabilité d’observer la preuve sachant l’affirmation ne soit pas trop petite ! C’est à dire qu’il faut que la preuve soit ordinaire si l’affirmation est vraie :
et donc que la probabilité d’observer la preuve sachant l’affirmation ne soit pas trop petite ! C’est à dire qu’il faut que la preuve soit ordinaire si l’affirmation est vraie :  .
. « les licornes existent » que l’on peut qualifier d’extraordinaire. J’y octroie a priori une probabilité de un sur un milliard :
« les licornes existent » que l’on peut qualifier d’extraordinaire. J’y octroie a priori une probabilité de un sur un milliard :  Pour que cette affirmation paraisse crédible, il faut donc observer une preuve
Pour que cette affirmation paraisse crédible, il faut donc observer une preuve  .
. : « Quelqu’un a vu de loin une silhouette de cheval avec une corne sur le front ». Ce n’est pas une preuve si extraordinaire : il a pu se tromper, c’était peut-être une installation artistique, des petits malins ont pu attacher un postiche ou il a menti. J’estime la probabilité d’observer cela à un sur mille. On a donc
: « Quelqu’un a vu de loin une silhouette de cheval avec une corne sur le front ». Ce n’est pas une preuve si extraordinaire : il a pu se tromper, c’était peut-être une installation artistique, des petits malins ont pu attacher un postiche ou il a menti. J’estime la probabilité d’observer cela à un sur mille. On a donc  . En revanche, il est clair que la probabilité que quelqu’un ait vu de loin une silhouette de cheval avec une corne sur le front sachant que les licornes existent est très élevée :
. En revanche, il est clair que la probabilité que quelqu’un ait vu de loin une silhouette de cheval avec une corne sur le front sachant que les licornes existent est très élevée :  .
. sachant
sachant 
 qui a une chance sur un milliard d’être observée : « J’ai fait 30 piles de suite ». La preuve est bien extraordinaire
qui a une chance sur un milliard d’être observée : « J’ai fait 30 piles de suite ». La preuve est bien extraordinaire  . Mais là encore la preuve ne satisfait qu’un seul des deux critères de la maxime de Hume baysésienne : elle est extraordinaire mais elle n’est pas ordinaire si l’affirmation est vraie. En effet, ici les deux évènements sont décorrélés : l’existence de licorne ne rend pas plus ordinaire une suite de 30 piles
. Mais là encore la preuve ne satisfait qu’un seul des deux critères de la maxime de Hume baysésienne : elle est extraordinaire mais elle n’est pas ordinaire si l’affirmation est vraie. En effet, ici les deux évènements sont décorrélés : l’existence de licorne ne rend pas plus ordinaire une suite de 30 piles  . Ça ne suffit donc pas à me convaincre. En l’occurrence la formule de Bayes donne:
. Ça ne suffit donc pas à me convaincre. En l’occurrence la formule de Bayes donne:
 un article scientifique corroboré par plusieurs chercheurs et fournissant suffisamment d’informations sur l’existence de licornes et étayé par des vidéos et des photos. Une telle preuve serait tout à fait extraordinaire en soi (estimée pour l’exemple à une chance sur 800 millions) et totalement ordinaire si l’affirmation est vraie (estimée ici à
un article scientifique corroboré par plusieurs chercheurs et fournissant suffisamment d’informations sur l’existence de licornes et étayé par des vidéos et des photos. Une telle preuve serait tout à fait extraordinaire en soi (estimée pour l’exemple à une chance sur 800 millions) et totalement ordinaire si l’affirmation est vraie (estimée ici à  ). La formule de Bayes donne alors :
). La formule de Bayes donne alors :
 .
.
















{kind=link}
{kind=link}
{kind=link}